Project# Pinecone VectorStore
Objective
Your manager asked you to explore Pinecone vector database for an upcoming initiative. You need to build a PoC and educate your team mates on how to use Pinecone for contextual searches (Similarity, MMR, Relevance search with scores). Since are new to Pinecone, so you need to understand how Pinecone works. Your manager has suggested that you go through the Pinecone documentation before proceeding.
Summary of tasks:
Part-1
- Create a free Pinecone account
- Learn about Pinecone indexes
- Read through the LangChain retriever for Pinecone
- Create a Pinecone index
- Setup environment variables to access the Pinecone index
Part-2
- Try out Pinecone for multiple types of searches
Tasks
Part-1
1. Create the Pinecone account (Free as of April 2024)
- Open Pinecode website
- You will need to provide an email-id or you can use social login
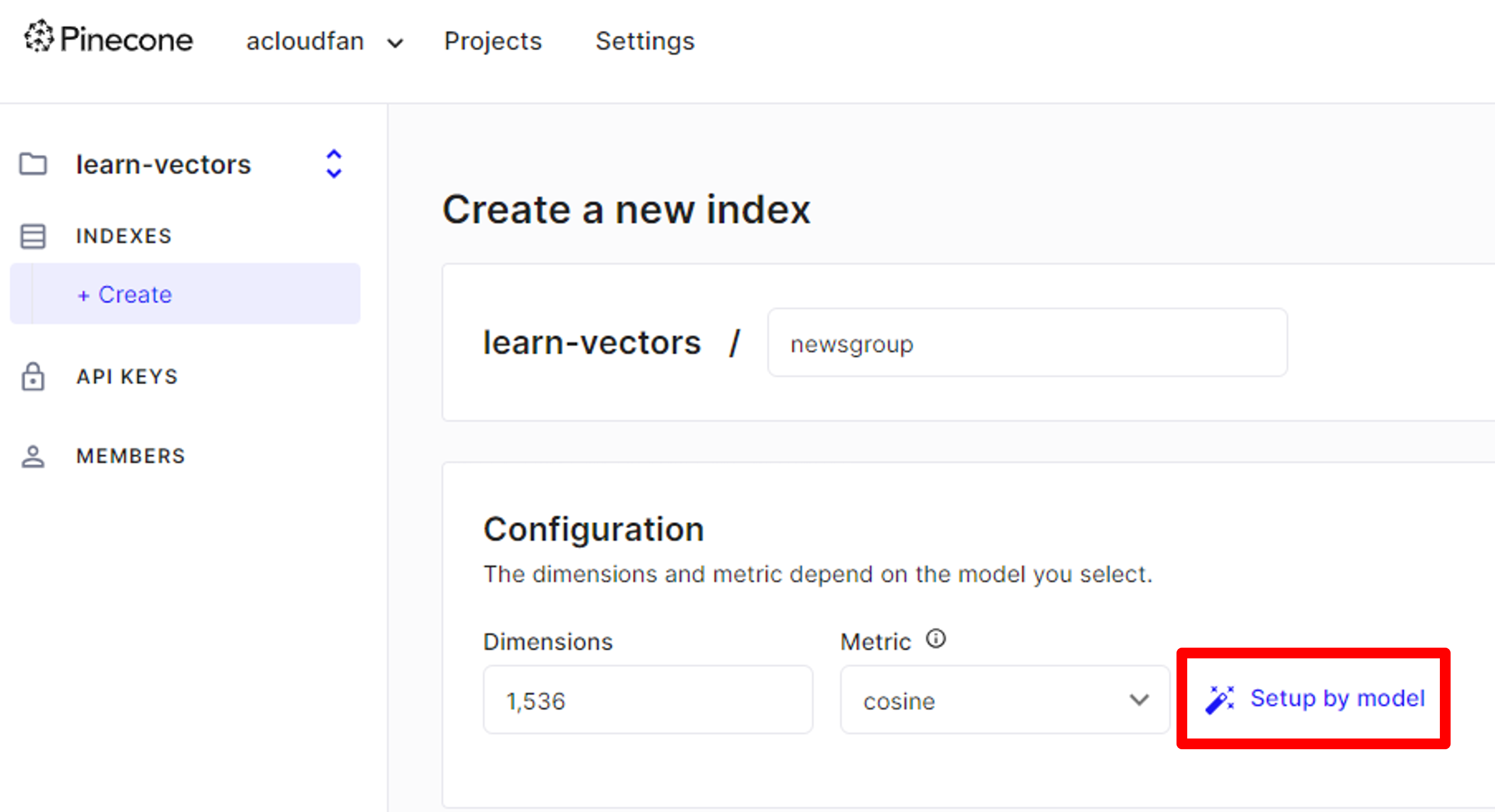
2. Use the Pinecone console to create an index
- Name the index : newsgroup
- Select the model to use (solution uses)
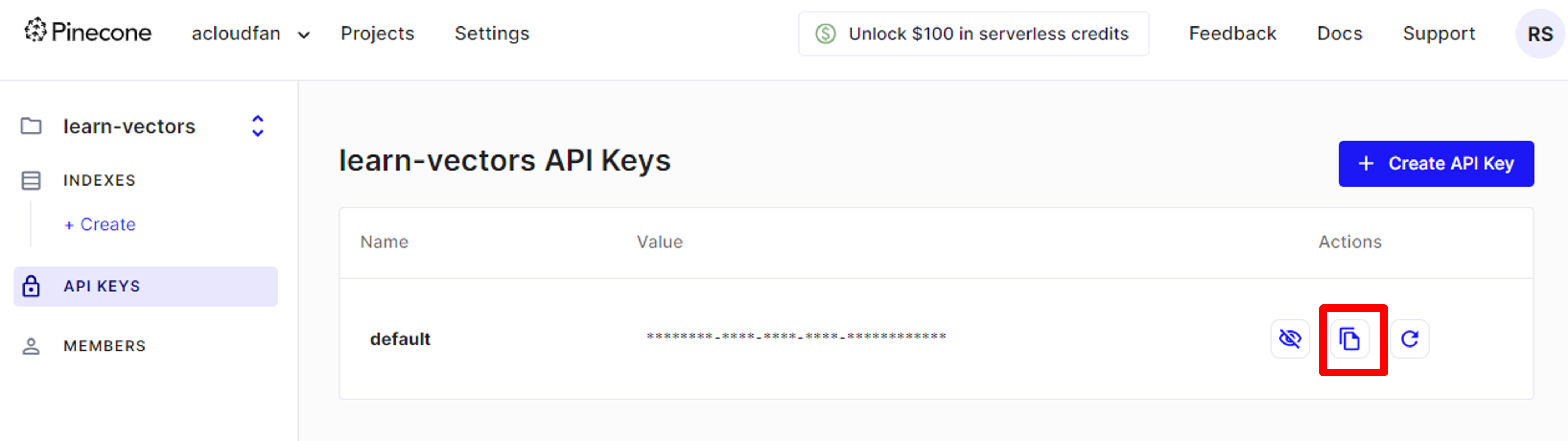
3. Setup Pinecone API key in your environment file
PINECONE_API_KEY=<COPY/Paste your Pinecone key here>
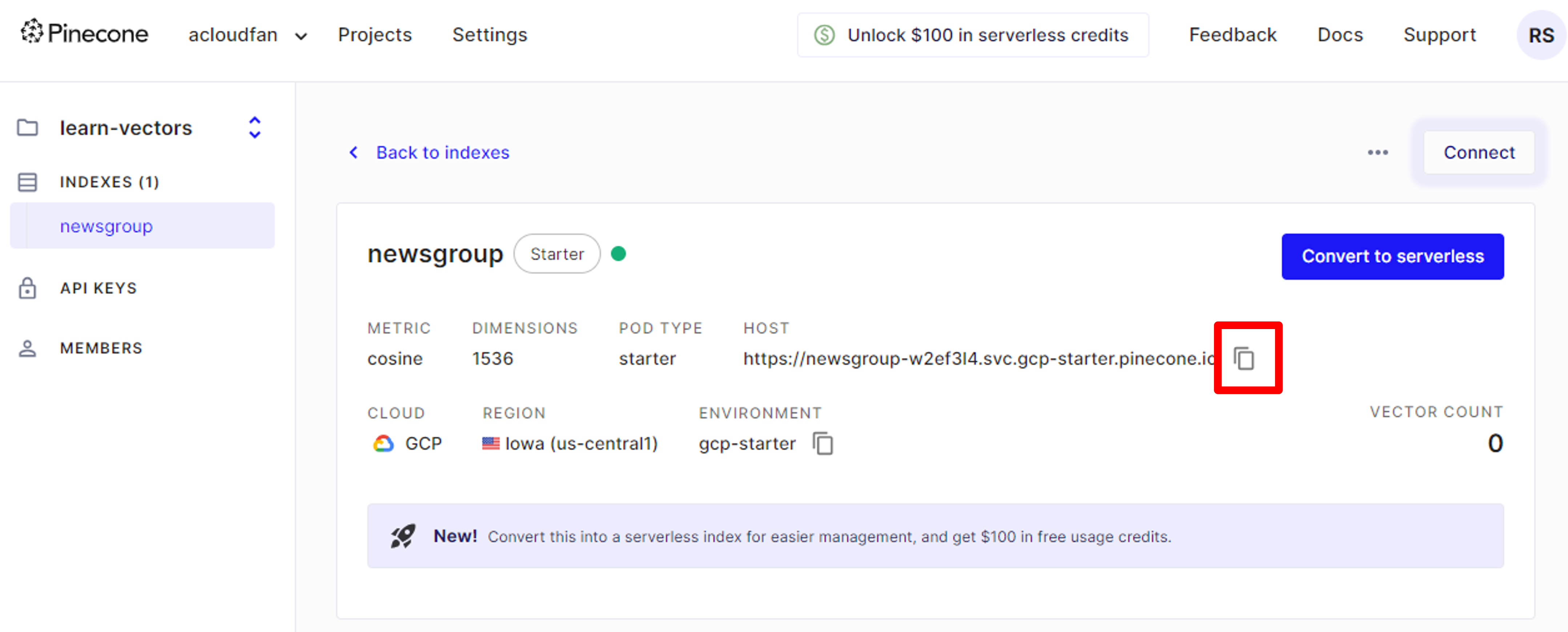
4. Setup Pinecone Hostname in your environment file
PINECONE_HOST=<COPY/Paste host name here>
5. Create a notebook and load the environment
from datasets import load_dataset
from dotenv import load_dotenv
import os
import warnings
from IPython.display import JSON
warnings.filterwarnings("ignore")
# Load the file that contains the API keys
load_dotenv('PROVIDE THE LOCATION OF YOUR Env File')
pinecone_api_key = os.environ.get('PINECONE_API_KEY')
openai_api_key = os.environ.get('OPENAI_API_KEY')
6. Setup Pinecone packages
You need to install the dependencies
!pip install --upgrade --quiet langchain-pinecone langchain-openai langchain
6. Load the data set
We will be using the newsgroup dataset in this exercise.
dataset_name = 'acloudfan/newsgroups-mini'
newsgroup_dataset = load_dataset(dataset_name)
# Split the 'train' split to test & train
newsgroup_dataset = newsgroup_dataset['train'].train_test_split(test_size=0.1)
newsgroup_dataset
Part-2
1. Convert the text to LangChain documents with metadata
from langchain_pinecone import PineconeVectorStore
from langchain.docstore.document import Document
from langchain_openai import OpenAIEmbeddings
pinecone_index_name = 'newsgroup'
index_dimension = 1536
train_docs = []
doc_ids = []
for row in newsgroup_dataset['train']:
doc_id = 'post-'+str(len(doc_ids))
doc_ids.append(doc_id)
# Add newsgroup name/class and id of the document as metadata
doc = Document(page_content=row['text'], metadata={'group': row['class'], 'id' :doc_id})
train_docs.append(doc)
len(train_docs)
2. Add the documents to the PineCone index
Read about Pinecone Upsert API in the documentation.
# Vector store requires access to the embedding model for converting the document to vector representation
openai_embeddings = OpenAIEmbeddings()
# Create the vector store db object - adds the documents with upsert behavior
pinecone_vdb = PineconeVectorStore.from_documents( train_docs, index_name = pinecone_index_name, embedding = openai_embeddings, ids=doc_ids)
3. Try out similarity search
# You need to setup the variables test_query & k
docs = pinecone_vdb.similarity_search(test_query, k = k)
4. Try out the MMR search; compare results with similarity search
lambda_mult = 0.5
docs = pinecone_vdb.max_marginal_relevance_search(test_query, k=3, fetch_k=10, lambda_mult=lambda_mult)
5. Search with relevance score
Read through the documentation on similarity_search_with_relevance_scores
6. Run similarity search with distance
Read through the documentation on similarity_search_with_score
Solution
The soultion to the exercise is available in the notebook below.
