Exercise#2 Multi Query Retriever
Objective
Learn to use LangChain Multi Query Retriever class.
LangChain Multi Query Retriever
Retrival flow
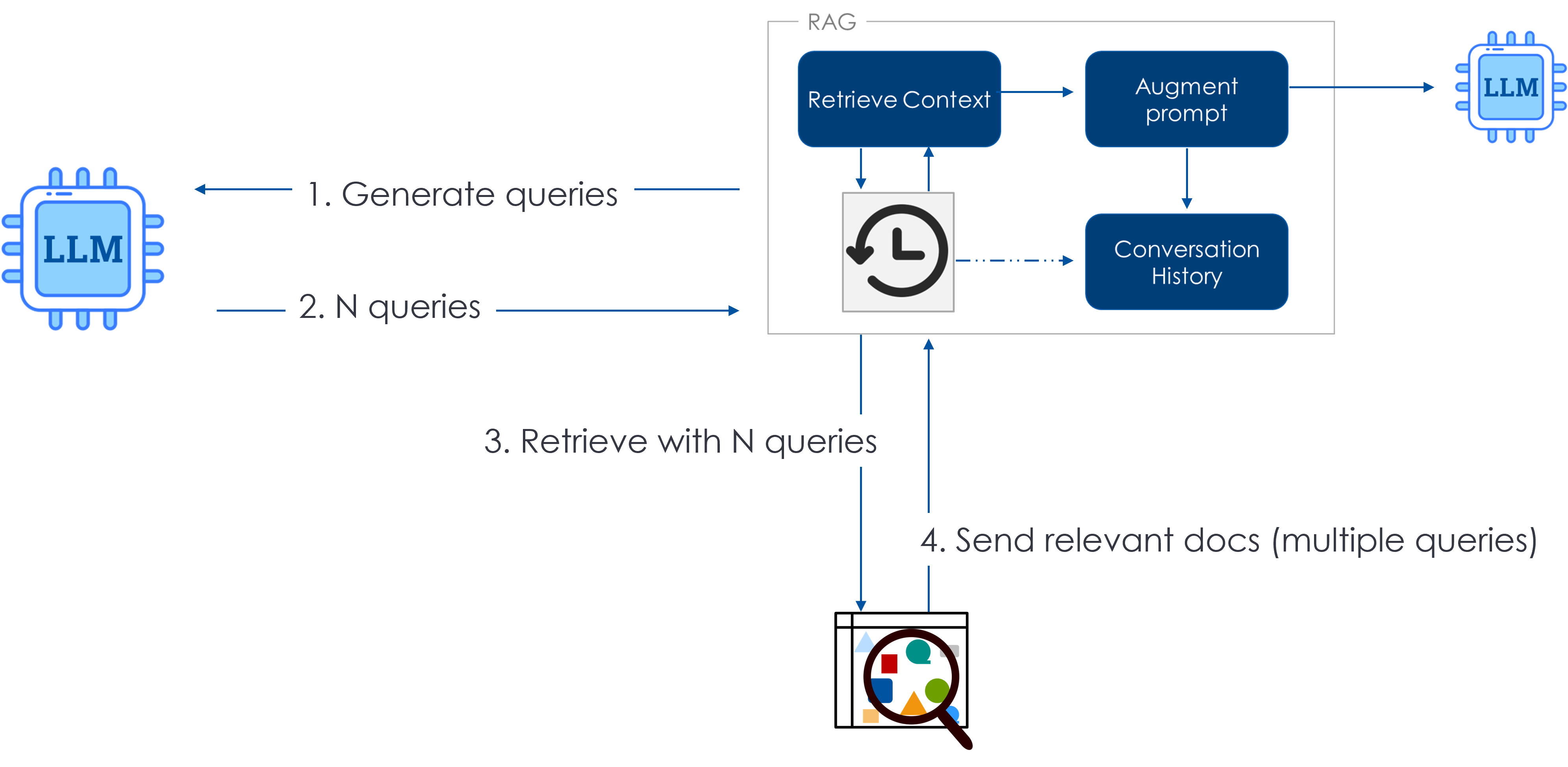
LangChain Multi Query Retrieval class
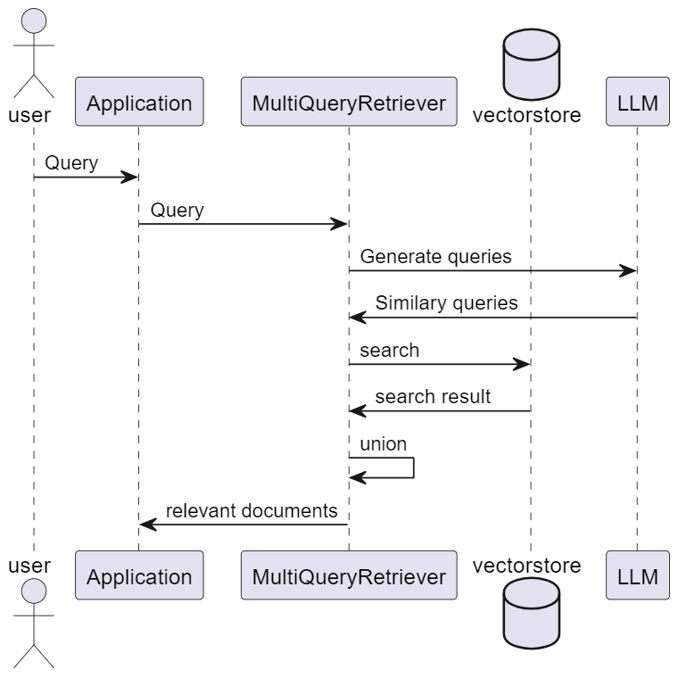
Steps
Create a new notebook and copy/paste the following code. Make sure to go through the code to understand what it is doing.
You MUST adjust the (1) path to the API key file (2) path for the util file depending on the location of notebook.
1. Setup LLM
Use the utility functions to create the LLM. Copy paste the facts below.
You MUST adjust the (1) path to the API key file (2) path for the util file depending on the location of notebook.
from dotenv import load_dotenv
import sys
import json
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
import logging
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
# Load the file that contains the API keys - OPENAI_API_KEY
load_dotenv('C:\\Users\\raj\\.jupyter\\.env')
# setting path
sys.path.append('../')
from utils.create_chat_llm import create_gpt_chat_llm, create_cohere_chat_llm
# Try with GPT
llm = create_cohere_chat_llm()
2. Create the Vectorstore
- Sample uses ChromaDB
- (optional) Replace VectorDB e.g., you may use PineCone
# Create the Chroma vector store
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(collection_name="full_documents", embedding_function=embedding_function)
# Load the docs
loader = DirectoryLoader('./util', glob="**/*.txt")
docs = loader.load()
# Smaller chunks stored in the vector DB
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=20)
chunked_documents = text_splitter.split_documents(docs)
# Add the documents to vector store
vector_store.add_documents(chunked_documents)
print(vector_store)
3. Setup Multi Query Retriever
# Create the retriever
retriever = vector_store.as_retriever()
# Create the MQR object
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=retriever,
llm = llm
)
# To check out the generated queries
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.DEBUG)
4. Checkout the behavior of MQR
# Test input
input = ["What is RAG?",
"How is fine tuning different than RAG?",
"What data is used to train ChatGPT?",
"What are the benefits of generative AI?"]
# Change index to select the question
ndx = 2
print("Question :", input[ndx])
results = multi_query_retriever.invoke(input = input[ndx])
print(results)
5. Create a retrieval chain
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
# Create Q&A chain
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# Create the chain with MQR
rag_chain = create_retrieval_chain(multi_query_retriever, question_answer_chain)
6. Test the chain
# vague question
input = "retrieval for context"
response = rag_chain.invoke({"input": input})
response['answer']
Solution
The solution to the exercise is available in the following notebook.
