Exercise#3 Parent Documents Retriever
Objective
Learn to use LangChain Parent Documents Retriever class.
LangChain Parent Documents Retriever
Indexing flow
Note: Depicts the option#2, where in the parent documents are returned as context
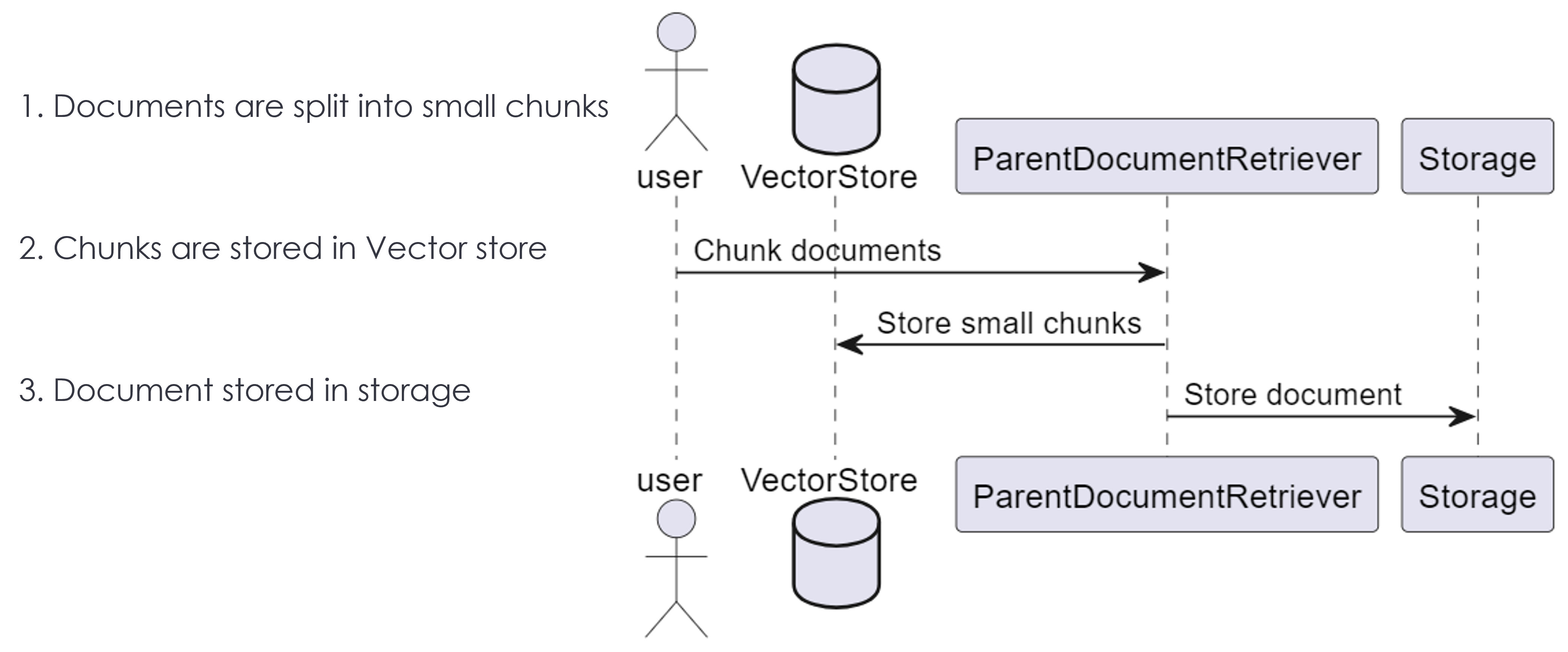
LangChain Parent Documents Retrieval class
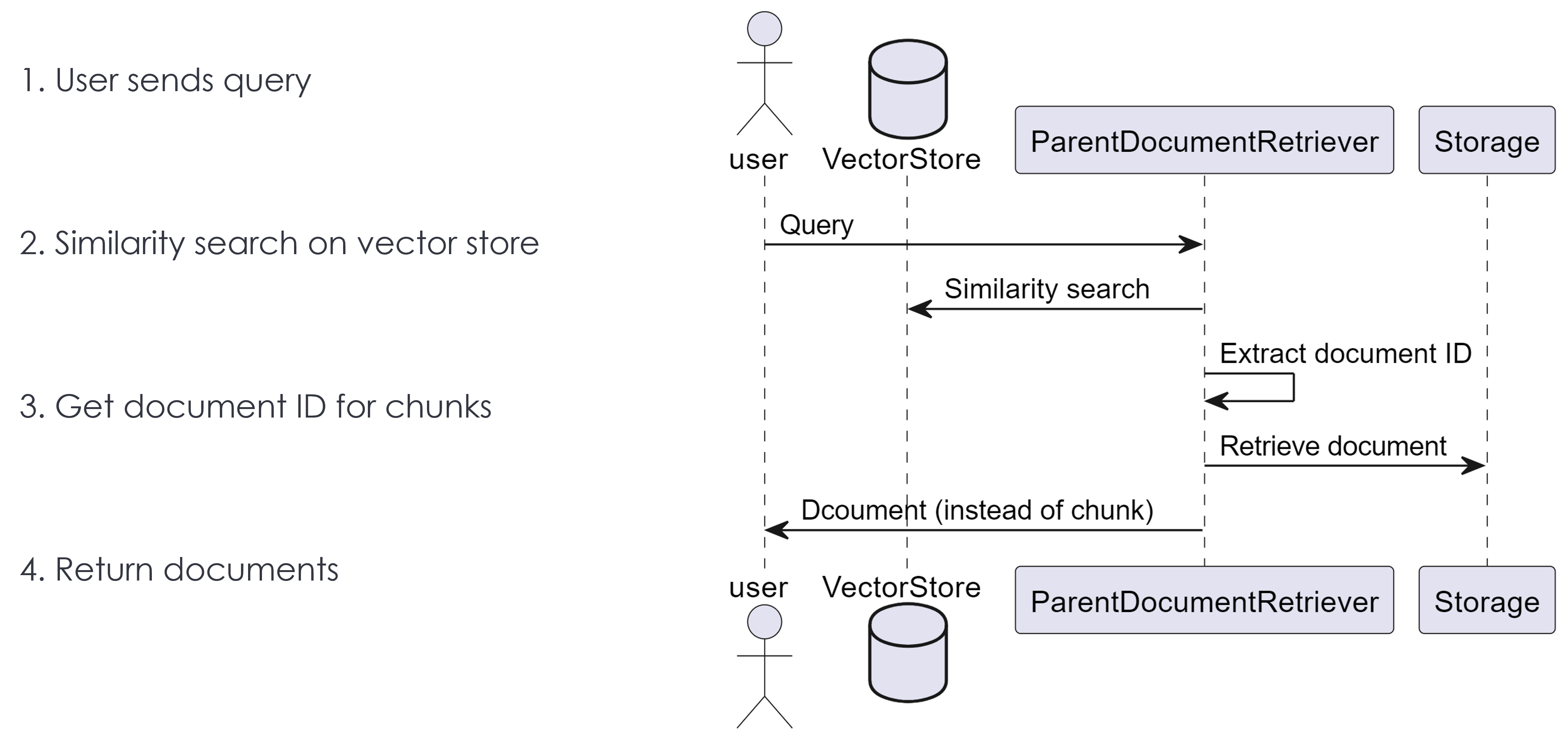
Steps
Create a new notebook and copy/paste the following code. Make sure to go through the code to understand what it is doing.
Sample reads .txt files from a subfolder. You will need to adjust the location of the folder otherwise the code will error out with FileNotFoundException. Test files are under a subfolder under RAG. Feel free to use different sets of test data files.
Import the required packages
from langchain.storage import InMemoryStore
from langchain.retrievers import ParentDocumentRetriever
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
import logging
1. Create Vectorstore, Child ext splitter
- Sample uses ChromaDB
- (optional) Replace VectorDB e.g., you may use PineCone
# Create the Chroma vector store
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(collection_name="full_documents", embedding_function=embedding_function)
# Smaller chunks stored in the vector DB
child_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=20)
2. Create the ParentDocumenRetriever
- A directory loader is used to read the text files from a folder
- Documents are added to the parent retriever using the add_documents function
- Sample uses the in memory storage, you may switch it with other storage types e.g., file system storage
# In memory dictionary to store parent docs
parent_doc_store = InMemoryStore()
# Create the retriever
# If parent splitter is NOT used then the entire document is returned
# If parnet splitter is used then the bigger-parent-chunks are returned
parent_retriever = ParentDocumentRetriever(
vectorstore=vector_store,
docstore=parent_doc_store,
child_splitter = child_splitter
)
# Add the data
loader = DirectoryLoader('./util', glob="**/*.txt")
docs = loader.load()
parent_retriever.add_documents(docs, ids=None)
3. Test the retriever behavior
- Run a query directly on the vector store, it will retrieve the small chunks
- Run the same query against the parent document retriever, the entire document will be returned
# Test input
input = ["What is RAG?",
"How is fine tuning different than RAG?",
"What data is used to train ChatGPT?",
"What are the benefits of generative AI?"]
# change input index for testing
ndx = 2
print(input[ndx],"\n")
print("Results from vector store retriever: ","\n")
results = vector_store.as_retriever().invoke(input[ndx])
for doc in results:
print("CHUNK: ", doc.page_content,"\n")
print("========================================")
print("Results from parent document retriever: ","\n")
# This will retrieve the entire document, instead of the chunk itself
results = parent_retriever.invoke(input[ndx])
# Print retrieved information to validate the behavior
print(results[0].page_content)
Solution
The solution to the exercise is available in the following notebook.
