Exercise#4 Ensemble Retriever
Objective
Learn to use LangChain Ensemble Retriever class.
Ensemble Retriever LangChain Ensemble Retriever
Ensemble Retriever flow
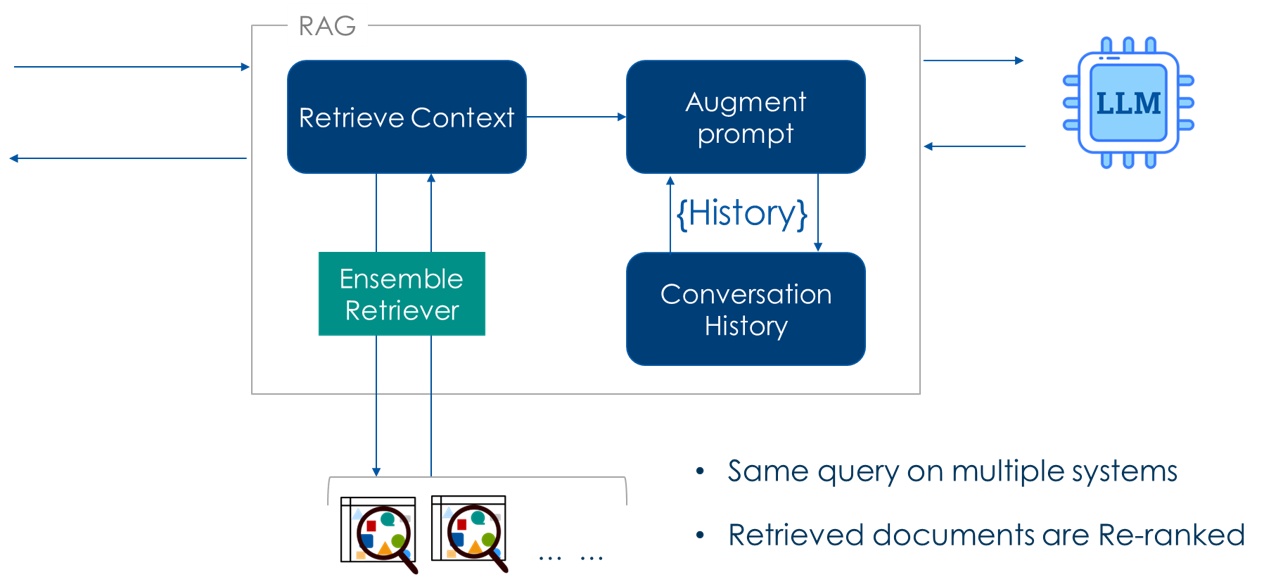
Steps
Create a new notebook and copy/paste the following code step-by-step. Make sure to go through the code to understand what it is doing.
Code use BM25Retriever which requires the rank_bm25 package to be installed (!pip install –upgrade –quiet rank_bm25)
- For BM25Retrieval install the rank_bm25 package
!pip install --upgrade --quiet rank_bm25
Import the required packages
from langchain_core.documents import Document
from langchain_community.retrievers import BM25Retriever
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.retrievers import EnsembleRetriever
1. Setup test corpus
- Setup corpus with simple documents
- Each document has metadata that holds information on the source
## 1. Create a test corpus
corpus = [
"RAG addresses hallucinations",
"Symptoms are hallucinations",
"RAG is easier than fine tuning",
"Use a RAG to clean it",
"Retrieval Augmented Generation"
]
corpus_docs = []
# Add metadata
for i, dat in enumerate(corpus):
document = Document(
page_content= dat,
metadata = {"source": "doc-"+str(i)}
)
corpus_docs.append(document)
# Print corpus
corpus_docs
2. Setup BM25 Retriever
- Sets up the retriever
- Documents with metada are indexed (added)
- Set the value of k = 3
# Create the BM25 Retriever
bm25_retriever = BM25Retriever.from_documents(corpus_docs, k=3)
3. Setup a vector store retriever
- Sample uses ChromaDB
- Add the documents with metadata
# Create instance of ChromaDB and add the
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(collection_name="full_documents", embedding_function=embedding_function)
vector_store.add_documents(corpus_docs)
# https://api.python.langchain.com/en/latest/vectorstores/langchain_community.vectorstores.chroma.Chroma.html#langchain_community.vectorstores.chroma.Chroma.as_retriever
chromadb_retriever = vector_store.as_retriever(search_kwargs={"k": 3})
4. Create the Ensemble retriever
- Pass the BM25 and ChromaDB as retrievers
- Set the weights for each retriever (0.4 for BM25, 0.6 for ChromaDB)
retrievers = [bm25_retriever, chromadb_retriever]
retriever_weights = [0.4, 0.6]
ensemble_retriever = EnsembleRetriever(
retrievers = retrievers,
weights = retriever_weights,
id_key = "source"
)
5. Test the Ensemble Retriever behavior
- Run a query for BM25
- Run same query for ChromaDB
- Run same query for EnsembleRetriever
- Checkout the ranking of the documents retrieved for each of the above
# Utility function to print the list of ranked documents
def dump_doc_source(result_documents):
for doc in result_documents:
print(doc.metadata["source"])
print("\n")
# Test input
input = ["rag is cheaper",
"benefits of rag",
"piece of cloth"
]
# change input index for testing
ndx = 0
print("Input: ", input[ndx],"\n")
# Dump the ranked list for BM25
print("BM25")
print("----")
results_bm25 = bm25_retriever.invoke(input[ndx])
dump_doc_source(results_bm25)
# Dump the ranked list for ChromaDB
print("ChromaDB")
print("--------")
results_chromadb = chromadb_retriever.invoke(input[ndx])
dump_doc_source(results_chromadb)
print("Ensemble Retriever")
print("------------------")
results = ensemble_retriever.invoke(input[ndx])
dump_doc_source(results)
results
Solution
The solution to the exercise is available in the following notebook.