Exercise#5 Multi Vector Retriever
Objective
Learn to use LangChain Multi Vector Retriever class for Hypothetical Questions embeddings strategy.
LangChain Multi Vector Retriever
Flow
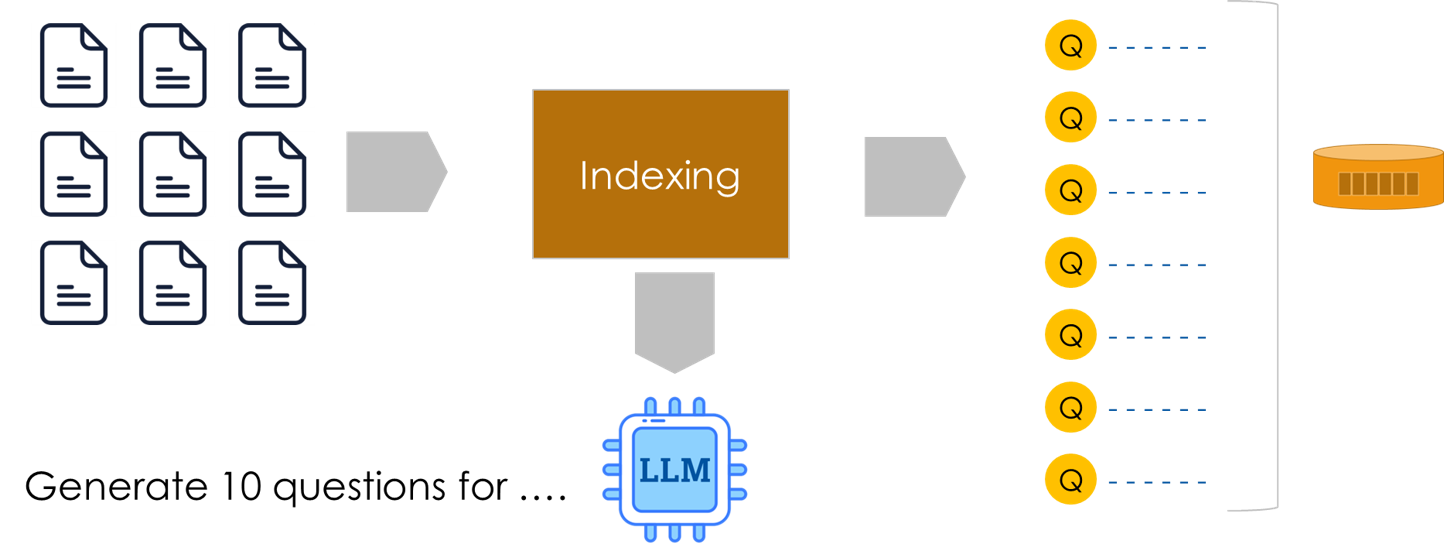
Steps
Create a new notebook and copy/paste the following code step-by-step. Make sure to go through the code to understand what it is doing.
You must adjust the location of the key file in code. Sample uses GPT 3.5 but you may use a different LLM - keep in mind that code/prompt adjustments may be needed in case different LLM.
Import the required packages
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.documents import Document
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.storage import InMemoryStore
from langchain.storage import LocalFileStore
from langchain.retrievers.multi_vector import MultiVectorRetriever
1. Create the LLM
- Sample is using GPT 3.5
- MUST changle location of the key file
from dotenv import load_dotenv
import sys
import json
# Load the file that contains the API keys - OPENAI_API_KEY
load_dotenv('C:\\Users\\raj\\.jupyter\\.env')
# setting path
sys.path.append('../')
from utils.create_chat_llm import create_gpt_chat_llm, create_cohere_chat_llm
# Try with GPT
llm = create_gpt_chat_llm()
2. Setup prompt for generating questions
- Sample uses entire document for generating the hypothetical questions
- Note that the output is in JSON formation
prompt_template = """
The provided document will be used as a context by a chatbot application.
You need to come up with a list 5 to 10 hypothetical questions that can be answered from this document
Output the questions as a valid JSON array.
Document:
{document}
Questions: [JSON array of questions]
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["document"])
3. Setup a Q&A chain
- prompt | LLM | JSONOutputParser
- Chain will be invoked for generating the Hypothetical Questions
# Create a parser
parser = JsonOutputParser()
# Set up a 3 step chain
qa_chain = prompt | llm | parser
4. Generate questions & create documents
- This may be done for chunks or entire document. Decision depends on the size of the document. To keep things simple we will do it for the entire document.
- Sample documents are read from a subfolder
- Questions are generated using the chain
- A LangChain Document is created with the question as the page content
- The document instances are added to a collection
- Adjust the subdirectory for the test documents
# Load sample docs - adjust the test data folder location
loader = DirectoryLoader('./util', glob="**/*.txt")
docs = loader.load()
questions_doc_collection = []
for i, doc in enumerate(docs):
input = prompt_template.format(document=doc.page_content)
questions = qa_chain.invoke(input)
# Ad doc_id to metadata
metadata = doc.metadata
metadata['doc-id'] = "doc-" + str(i)
# Create documents from questions
for question in questions:
document = Document(page_content=question, metadata=metadata)
questions_doc_collection.append(document)
# questions_doc_collection
5. Create ChromaDB Vector Store
- You may use a different vector store such as Pinecone, FAISS …
# Create instance of ChromaDB & add the documents
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store = Chroma(collection_name="full_documents", embedding_function=embedding_function)
vector_store.add_documents(questions_doc_collection)
vector_store_retriever = vector_store.as_retriever()
# (Optional) test the retriever
#print(vector_store_retriever.invoke("what is RAG"))
#print(vector_store_retriever.invoke("what is fine tuning"))
6. Create MultiVectorRetriever
- Uses the File System Store that manages the documents on the filesystem
- Read through the API documentation for the MultiVectorRetriever class
- Files are stored in the subfolder named ./temp
- Source document ID is available in the metadata attribute named doc-id
# The storage layer for the parent documents
file_store = LocalFileStore("./temp")
# Loop through the docs and add to file store
# This may be moved to earlier cell for performance but kept here for clarity
for doc in docs:
file_store.mset([(doc.metadata['doc-id'],doc.page_content.encode())])
# Create the multi vector class instance
mvr_retriever = MultiVectorRetriever(
vectorstore=vector_store,
docstore=file_store,
id_key="doc-id",
)
7. Test
- Test directly against the vector store
- Test the vector store retrieval
# Test question = input
question = "what is gpt and rag"
# Get the similar questions from vector store
print("Direct query against the vector store")
print("-------------------------------------")
vector_store_retriever_results = vector_store_retriever.invoke(input=question)
print(vector_store_retriever_results)
# Get the context
print("\nQuery against the MVR. Number of docs = ", len(mvr_retriever_results))
print("-----------------------------------------------")
mvr_retriever_results = mvr_retriever.invoke(input=question)
print(mvr_retriever_results)
Solution
The solution to the exercise is available in the following notebook.
