Exercise#6 Large Context Reorder
Objective
Learn to use LangChain Large Context Reorder class.
LangChain Large Context Reorder
Flow
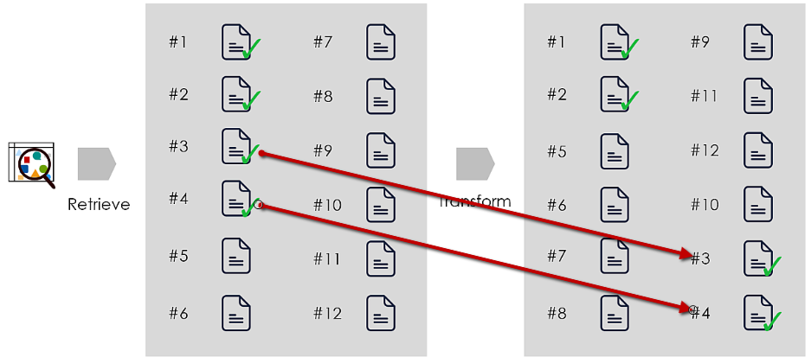
Steps
Create a new notebook and copy/paste the following code step-by-step. Make sure to go through the code to understand what it is doing.
Import the required packages
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.document_transformers import LongContextReorder
1. Setup test corpus
- Contains 4 rows that are related to Retrieval Augmented Generation (RAG). To answer RAG related questions LLM should use only these 4 rows.
- Rest of the rows are not related to RAG
# First 4 rows are related to RAG=Retrieval Augmented Generation
# Rest of the rows are related to rags of clothing
data = [
"RAG retrieves relevant documents to inform generation.",
"RAG is used in open-domain question answering.",
"The retrieval component in RAG finds pertinent information quickly.",
"RAG can handle complex queries with more precision.",
"Old t-shirts make great cleaning rags.",
"Rags are perfect for dusting furniture.",
"Use rags to clean up spills quickly.",
"Cut up old towels for durable rags.",
"Rags can be reused multiple times.",
"Keep rags handy in the kitchen for quick cleanups.",
"Rags made from cotton are highly absorbent.",
"Store rags in a bucket for easy access.",
"Rags are useful for polishing shoes.",
"Recycle old clothes into rags instead of throwing them away."
]
2. Create the Vector Store
- Sample uses ChromaDB
# Create instance of ChromaDB and add the documents
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# Create a vector store from
vector_store= Chroma.from_texts(data, embedding=embedding_function)
vector_store_retriever = vector_store.as_retriever(search_kwargs={"k": 10})
3. Create Long Context Reorderer
- Go through the API documentation
# Create the long context reorder
reordering_retriever = LongContextReorder()
4. Test: Result with & without reordering
# Print the context
def dump_results(docs):
for doc in docs:
print(doc.page_content)
# Test question = input
question = "what is gpt and rag"
# Get the similar questions from vector store
print("Original ordering of context")
print("----------------------------")
vector_store_retriever_results = vector_store_retriever.invoke(input=question)
dump_results(vector_store_retriever_results)
print("\nRe-ordered context")
print("-------------------")
# Reorder the documents
reordered_docs = reordering_retriever.transform_documents(vector_store_retriever_results)
dump_results(reordered_docs)
Solution
The solution to the exercise is available in the following notebook.