Exercise#8 Merger Retriever
Objective
Learn to use LangChain Merger Retriever a.k.a. LOTR class.
EnsembleRetriever vs MergerRetriever
Flow
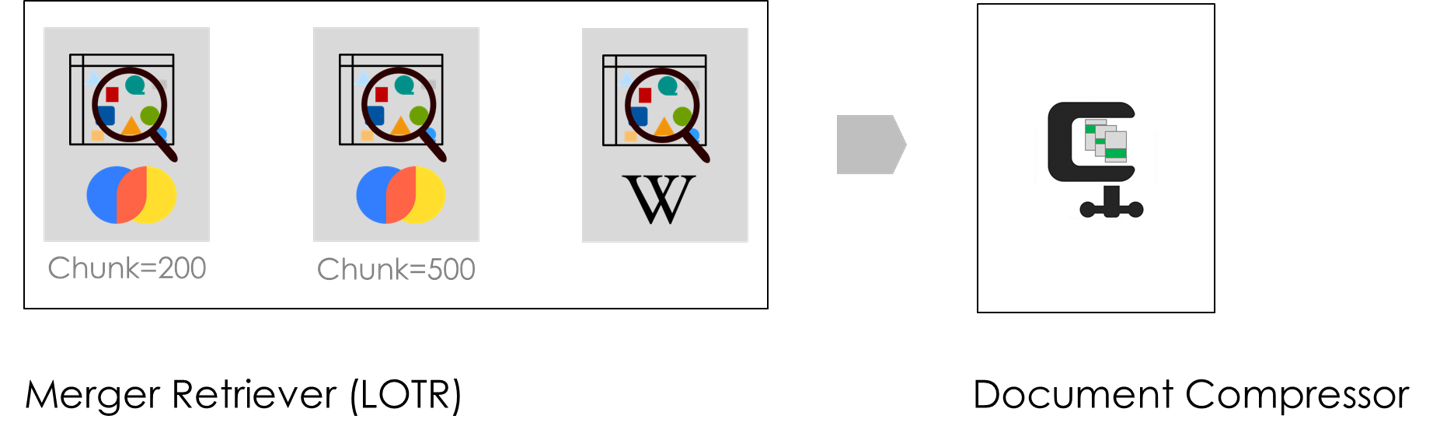
Steps
Create a new notebook and copy/paste the following code step-by-step. Make sure to go through the code to understand what it is doing.
Import the required packages
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.documents import Document
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Retrievers & transformers
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers import MergerRetriever
# Embeddings
from langchain_cohere import CohereEmbeddings
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.documents import Document
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
1. Create an LLM
- Cohere command model
- Cohere embedding model
from dotenv import load_dotenv
import sys
import json
# Load the file that contains the API keys - OPENAI_API_KEY
load_dotenv('C:\\Users\\raj\\.jupyter\\.env')
# setting path
sys.path.append('../')
from utils.create_chat_llm import create_gpt_chat_llm, create_cohere_chat_llm
# Try with GPT
llm = create_cohere_chat_llm()
llm_embeddings = CohereEmbeddings()
2. Utility function
- Prints the size information
- Pretty prints the documents
def print_documents(docs):
for i, doc in enumerate(docs):
print("#",i)
print(doc.page_content)
def dump_results_info(result):
print("Doc count = ", len(result))
page_content_length=0
for doc in result:
page_content_length = page_content_length + len(doc.page_content)
print("Context size = ", page_content_length)
print_documents(result)
3. Setup VectorDB retrievers
- Create 2 vector stores with different chunks sizes (200 & 500)
- using ChromaDB as a retriever
Chunk size = 200, search_type=similarity
# Create the Chroma vector store #1
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store_1 = Chroma(collection_name="rag_documents", embedding_function=embedding_function)
# Load sample docs
loader = DirectoryLoader('./util', glob="**/*.txt")
docs = loader.load()
# Chunking
doc_splitter_1 = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
chunked_documents_1 = doc_splitter_1.split_documents(docs)
# Add to vector DB
vector_store_1.add_documents(chunked_documents_1)
# Base retrievers
vector_store_retriever_1 = vector_store_1.as_retriever(search_type="similarity", search_kwargs={"k": 5})
Chunk size = 500, search_type=mmr
# Create the Chroma vector store #2
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vector_store_2 = Chroma(collection_name="rag_documents", embedding_function=embedding_function)
# Chunking
doc_splitter_2 = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunked_documents_2 = doc_splitter_2.split_documents(docs)
# Add to vector DB
vector_store_2.add_documents(chunked_documents_2)
# Base retrievers
vector_store_retriever_2 = vector_store_2.as_retriever(search_type="mmr", search_kwargs={"k": 5})
4. Wikipedia Retriever
from langchain_community.retrievers import WikipediaRetriever
wikipedia_retriever = WikipediaRetriever(search_kwargs={"k": 5})
5. Combine retrievers using Merger Retriver
# The 2 vector retriever and 1 wiki retriever
merger_retriever = MergerRetriever(retrievers=[vector_store_retriever_1,vector_store_retriever_2, wikipedia_retriever])
6. Apply document compressor
# Create embedding clustering filter
filter_ordered_by_retriever = EmbeddingsClusteringFilter(
embeddings=llm_embeddings,
num_clusters=5,
num_closest=1,
sorted=True,
)
# Create document compressor pipeline
pipeline = DocumentCompressorPipeline(transformers=[filter_ordered_by_retriever])
# Create compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline, base_retriever=merger_retriever
)
7. Test
question = "what is rag in generative ai?"
bef = merger_retriever.invoke(question)
dump_results_info(bef)
aft = compression_retriever.invoke(question)
dump_results_info(aft)
Solution
The solution to the exercise is available in the following notebook.
