Exercise#3 Multi step agent
Objective
Learn how multi step agents that use ReAct prompt work under the covers. Code shows how to build a Question Answering system that answers the questions by generating reasoning traces.
The code below uses GPT3.5-turbo model. Code requires the TAVILY_API_KEY to be set in the key file.
The code does not use the Langchain Tool or Agent classes as the intent is to show you the internal working of multi-step ReAct agent.
The code uses Tavily search tool. You will need to register with Tavily to get a API key.
Tools
You will setup two tools for this exercise.
- Wikipedia tool
- Tavily search tool : for internet searches
- Register with Tavily (Free plan) for API key
- Add the key from the developer page to your key file
- TAVILY_API_KEY=YOUR_TAVILY_API_KEY
Agent logic
Agent is implemented to run four steps:
Step-1 Generate plan with actions
Step-2 Invoke tools
Step-3 Send tool response to LLM
Step-4 If LLM response has answer : Task is complete OTHERWISE go-to:Step-2
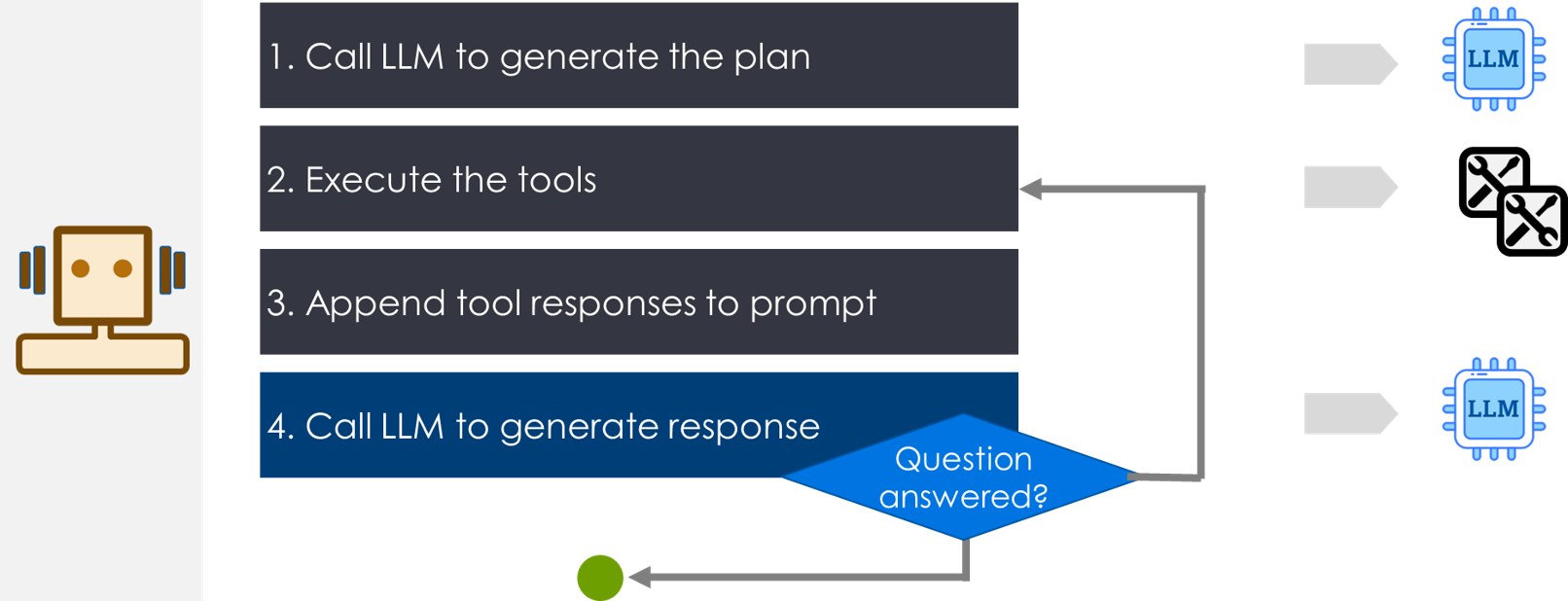
Steps
Setup LLM
Note
- You MUST change the location of the API key file.
- You MUST add TAVILY_API_KEY to the key file before running this cell
from dotenv import load_dotenv
import sys
import json
import time
from langchain.prompts import PromptTemplate
# Load the file that contains the API keys - OPENAI_API_KEY, AVILY_API_KEY
# CHANGE THE LOCATION
load_dotenv('C:\\Users\\raj\\.jupyter\\.env')
# setting path
sys.path.append('../')
from utils.create_chat_llm import create_gpt_chat_llm, create_cohere_chat_llm, create_anthropic_chat_llm, create_hugging_face_chat_llm
from utils.create_llm import create_cohere_llm, create_gpt_llm
# Try with GPT
llm = create_gpt_chat_llm({"temperature":0.01})
Setup tools
- Learn about Tavily
- (optional) Try out Tavily in a scratch notbook
from langchain.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_community.tools.tavily_search import TavilySearchResults
# Create Wikipedia tool
wikipedia_tool = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
# Reads AVILY_API_KEY from the environment. Loaded from key file
# Note : Does not require separate package or wrapper
# https://api.python.langchain.com/en/latest/tools/langchain_community.tools.tavily_search.tool.TavilySearchResults.html
tavily_tool = TavilySearchResults(include_raw_content=True, include_answer=True, max_results=2)
# Setup tools description in JSON format
toos_json = [
{
"name": 'wikipedia',
"description": wikipedia_tool.description,
"arguments": [
{
"input": "input"
}
],
"response": "search results"
},
{
"name": 'tavily',
"description": tavily_tool.description,
"arguments": [
{
"input": "input"
}
],
"response": "search results"
}
]
# Convert to string
tools = json.dumps(toos_json, indent=4)
# Setup tools map - so agent can map the name to function
tools_map = {
'wikipedia': wikipedia_tool.invoke,
'tavily' : tavily_tool.invoke
}
print(tools)
1. ReAct prompt
- Carefully review the prompt
- Identify the difference between this and single step agent prompt used in earlier exercise
- Structure of prompt:

prompt_template = """
You are a helpful assistant capable of answering questions on various topics.
Do not use your internal knowledYou MUST validate the answer using tools to access external tools.
Instructions:
Take an iterative approach. In each iteration:
1. Thought : Think step by step. Use alternatives as needed.
2. Action : Execute appropriate tools. Try alternative tool if an appropriate response is not received.
3. Observations : Make observations based on the responses from the tools and decide the next step
Repeat this Thought/Action/Observation process N times till either you get the answer or are unable to get the answer using the available tools.
Use only the following available tools to find information.
Tools Available:
{tools}
Guidelines for Responses:
Format 1: If the question cannot be answered with ANY of the available tools, use this format. 'actions' contain alternate tools to be run:
{{
"answer": "No appropriate tool available",
"actions": [
{{
"action": tool name,
"arguments": dictionary of argument values
}}
],
"scratchpad": {{
"thought": "your inner thoughts",
"action": "tool name",
"observations": "your observations from the tool responses"
}}
}}
Format 2: If you need to run tools to obtain the information, use this format:
{{
"actions": [
{{
"action": tool name,
"arguments": dictionary of argument values
}}
],
"scratchpad": {{
"thought": "your inner thoughts",
"action": "tool name",
"observations": "your observations from the tool responses"
}}
}}
Format 3: If you can answer the question using the responses from the tools, use this format:
{{
"answer": "your response to the question",
"scratchpad": {{
"thought": "your inner thoughts",
"action": "tool name",
"observations": "your observations from the tool responses"
}}
}}
Do not run a tool again with same arguments, use tool responses from previous runs of the tool.
Avoid any preamble; respond directly using one of the specified JSON formats.
Question:
{question}
Tool Responses:
Your response:
"""
prompt = PromptTemplate(
template = prompt_template,
input_variables = ["tools", "question"]
)
3. Agent code : Processing in ONE iteration
- Create a functions for invoking the LLM and the tools
- Invokes the LLM with input
- If tools need to be executed, runs tools
- return the LLM response and tool execution responses
# Returns : raw LLM response JSON, tools execution responses JSON or Answer JSON
def invoke_llm_and_tools(input):
# Invoke LLM
# The response may consist of tools that LLM requires to be executed
response = llm.invoke(input)
# print the response
print("LLM Response: ", response.content)
# Convert response to JSON object. The response is of type AIMessage
response_json = json.loads(response.content)
tool_responses=[]
if "actions" in response_json:
# If the LLM has suggested tools to be executed, execute the tools
tool_responses = { "action_responses": invoke_tools(response_json)}
elif "answer" in response_json:
# If the answer is already there
return response_json, {"answer" : response_json["answer"]}
return response_json, tool_responses
- Create a utility function for invoking the tools
# Utility function to invoke the tools
# Uses the tools map to get the function based on the tool
def invoke_tools(llm_response):
action_responses = []
if len(llm_response["actions"]) == 0:
print('no actions need to be run')
else:
# Run all tools suggested by LLM
for action in llm_response["actions"]:
# Get the function pointer from the map
action_function = tools_map[action["action"]]
# Invoke the tool/function with the arguments as suggested by the LLM
action_invoke_result = action_function(**action["arguments"])
action["action_response"] = action_invoke_result
# Add the response to the action attribute
action_responses.append(action)
# Return the response
return action_responses
4. Agent loop
- Setup maximum number of iterations and maximum execution duration
- Needed to prevent run-away executions (infinite loop)
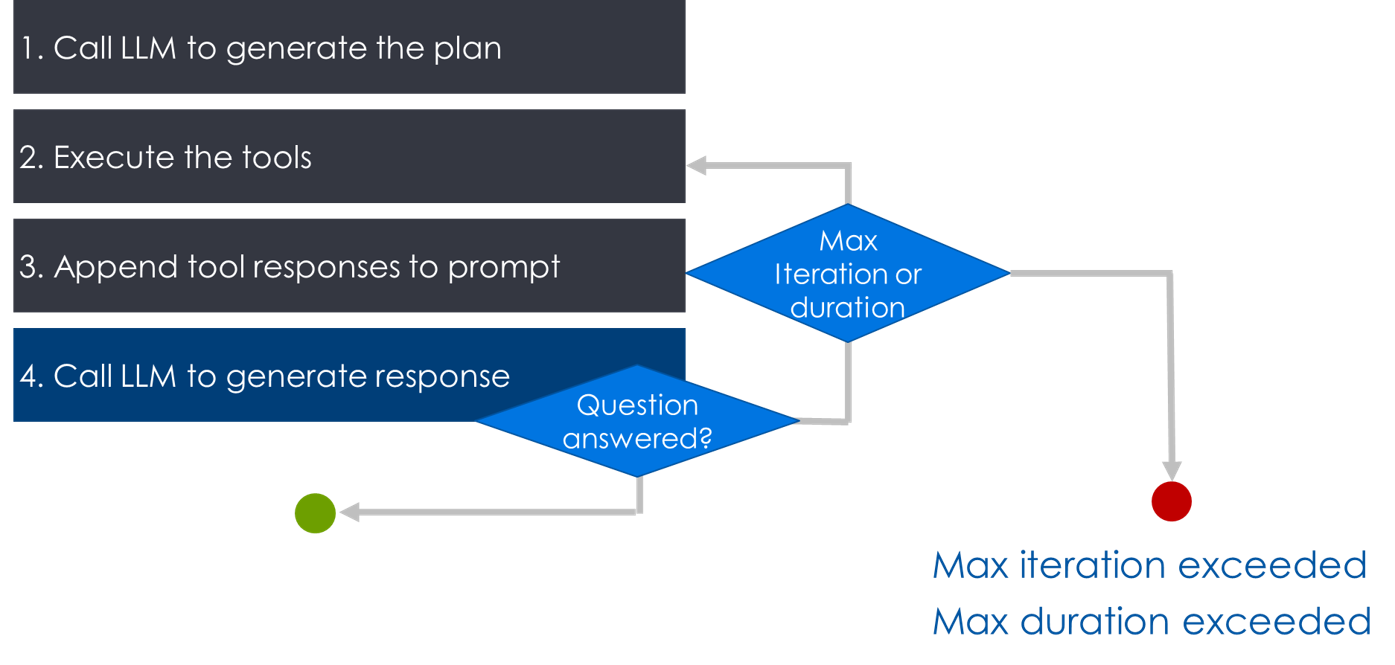
# Maximum allowed iterations to prevent runaways
max_iterations = 4
# Maximum allowed duration in milliseconds to prevent runaways
# Default set to 20 seconds
max_execution_time = 20000
- Agent loop
- Repeatedly calls the function : invoke_llm_and_tools
# Run a loop to call : invoke_llm_and_tools
# Loop stop reasons:
# ANSWER, NO_APPROPRIATE_TOOL, MAX_ITERATION_EXCEEDED, MAX_EXECUTION_TIME_EXCEEDED
# Returns: Stop-reason, last input sent to LLM, answer or {}
def multi_step_agent_loop(question):
iteration_number = 1
# Setup the input from prompt template
input = prompt.format(tools=tools, question=question)
# Setup start time
start_time_millis = round(time.time() * 1000)
# loop
while iteration_number <= max_iterations:
# print
print("ITERATION# : ", iteration_number )
print("===================")
# Invoke LLM and tools : single iteration
llm_response, action_response = invoke_llm_and_tools(input)
# Check if there is an answer attribute in the response and no further actions proposed
if "answer" in llm_response and "actions" not in llm_response:
answer = action_response['answer']
return "ANSWER", input, answer
elif len(action_response) == 0:
# No tool executed = No appropriate tool available
return "NO_APPROPRIATE_TOOL", input, {}
else:
# Augment the input with:
# 1. Response from LLM
# 2. Response from tools
# 3. Output indicator (Your response:)
input = input + "\n"+ json.dumps(llm_response) + "\nTool responses: \n" + json.dumps(action_response) + "\n Your response: "
# Increment the transaction number
iteration_number = iteration_number + 1
# Make sure we have not exceeded the execution time
current_time_millis = round(time.time() * 1000)
if (current_time_millis - start_time_millis) > max_execution_time:
return "MAX_EXECUTION_TIME_EXCEEDED", input, {}
# Exceed the max allowed iterations
return "MAX_ITERATION_EXCEEDED", input, {}
Testing
- Uncomment the desired question to try out the test
- You may pick questions from the HotPotQA dataset
- Try multiple/varied questions
- (Optional) Switch LLM or/and tools :)
Keep in mind that the quality of results depend on the LLM and quality of search results. E.g., search engine returns little information on a topic the answers may be anaemic or even incorrect.
# Q: Risingson is the first single from what album by Massive Attack, that was the first to be produced by Neil Davidge, along with the group?
# A: Mezzanine
# question = "Risingson is the first single from what album by Massive Attack, that was the first to be produced by Neil Davidge, along with the group?"
# Q: Where is the basketball team that Mike DiNunno plays for based ?
# A: Ellesmere Port
# question = "Where is the basketball team that Mike DiNunno plays for based ?"
# Q: Which one of Ricardo Rodríguez Saá's relatives would become governor from 1983 to 2001?
# A: Adolfo Rodríguez Saá
question="Which one of Ricardo Rodríguez Saá's relatives would become governor from 1983 to 2001?"
stop_reason, input, answer = multi_step_agent_loop(question)
print("Answer : ", answer)
print("Stop reason : ", stop_reason)
Solution
The solution to the exercise is available in the following notebook.
Optional exercises
- Use a different LLM. Keep in mind you may need to adjust the prompt
- Add different or more tools
- Try out complex logical, reasoning & factual questions