Exercise#3 Prepare and tune 4o
Objective
The objective is to learn how to prepare a dataset for fine-tuning.
Steps
1. Review the dataset requirements
Open AI fine tuning requirements
2. Write data pre-processing code
The data prep-processing code will:
1. Read Parquet files provided to you
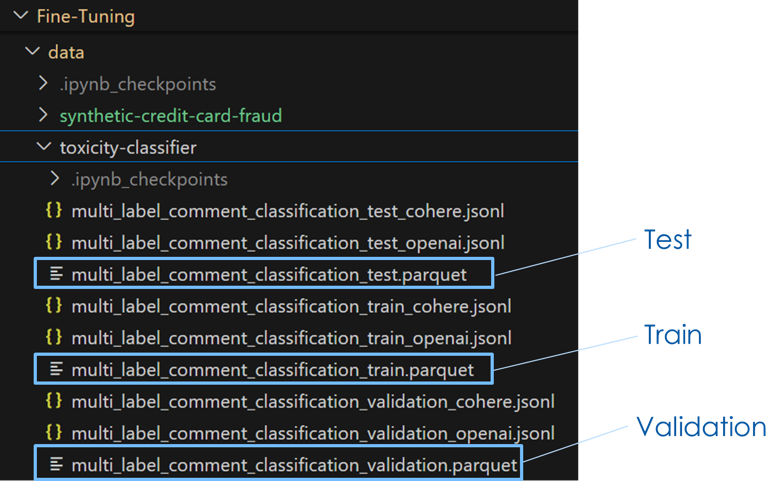
2. Structure the data in the required format.
Dataset for Open AI 4o mini model needs to be in chat format. Here is a sample:
{
"messages":[
{"role":"system","content":"you will categorize the user's input into one or more categories: ['toxic', 'severe_toxic', 'threat', 'insult', 'identity_hate']"},
{"role":"user","content":"\"\"\"Nazi filth\"\" is impolite 04:27, 20 Jan 2004 (UTC)\n\n\""},
{"role":"assistant","content":"[\"toxic\", \"insult\"]"}
]}
3. Write out the data in JSONL format
- Notice that there are 3 splits
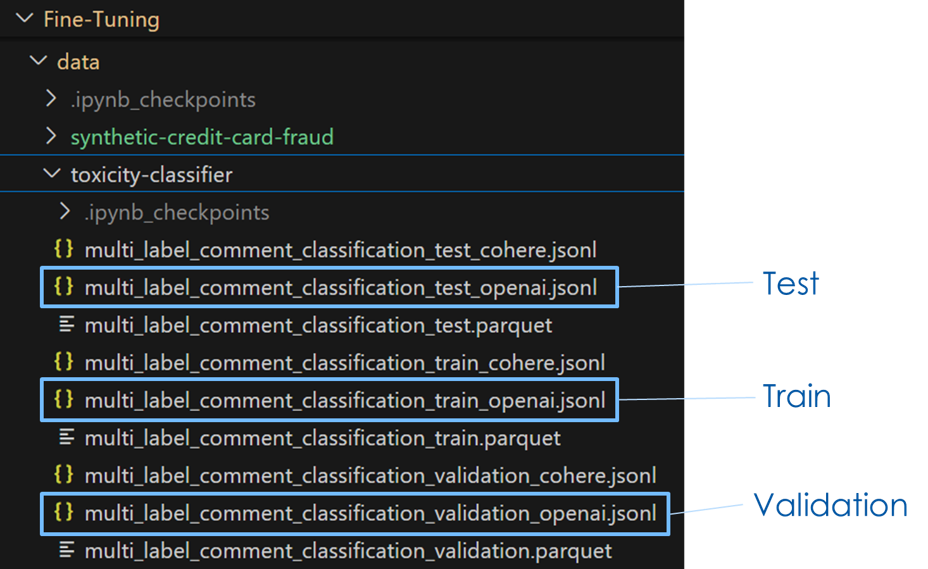
4. Use the data files to fine-tune open AI 4o mini model
5. Use the Open AI dashboard to compare the performance
Default hyperparameters were used for model fine-tuning. No attempt was made to make the model more accurate. You will learn how to adjust hyperparameters in a later lesson.
- Open the fine-tuning dashboard
- Select the fine-tuned model and click on playground
- Provide the system prompt
You are responsible for content moderation for a public forum.
For the given comment you will categorize the user's input into one or more categories: ['toxic', 'severe_toxic', 'threat', 'insult', 'identity_hate']
- Test the model’s output using samples from test dataset
Ech, you silly Mensans, you have IQ points to spar
Actual: [“toxic”,“insult”]
Look, you're a pedant, and Fetzer is a Jew-hater. On Press TV in the UK today - September 2nd 2011 - he said that the Israelis were behind 9\/11. The man is a complete fool
[“toxic”,“insult”,“identity_hate”]
Solution